In this article, we mention AWS but the content applies to all cloud providers (Azure, GCP, Azure, DigitalOCean etc) as well. Node.js is also used as proxy for all other programming frameworks/languages.
This article is a continuation of Basics of scaling Node.js applications on AWS. The expectation is you have read that article to familiarize yourself with how to manually scale applications on NodeChef.
Auto scaling allows you to add and remove containers dynamically in response to a change in a specific metric captured. The metric could be anything from CPU usage, memory usage, response latency of your application containers to incomming requests, containers per HTTP(s) connections ratio as well as containers per open websockets ratio. All of these metrics provide a robust way to define rules that will allow you to dynamically size your deployment.
To set rules, navgiate to the Task manager and click on App actions → container rules for your app. You can also find the container rules under Deployments → Deployed apps → Cluster actions.
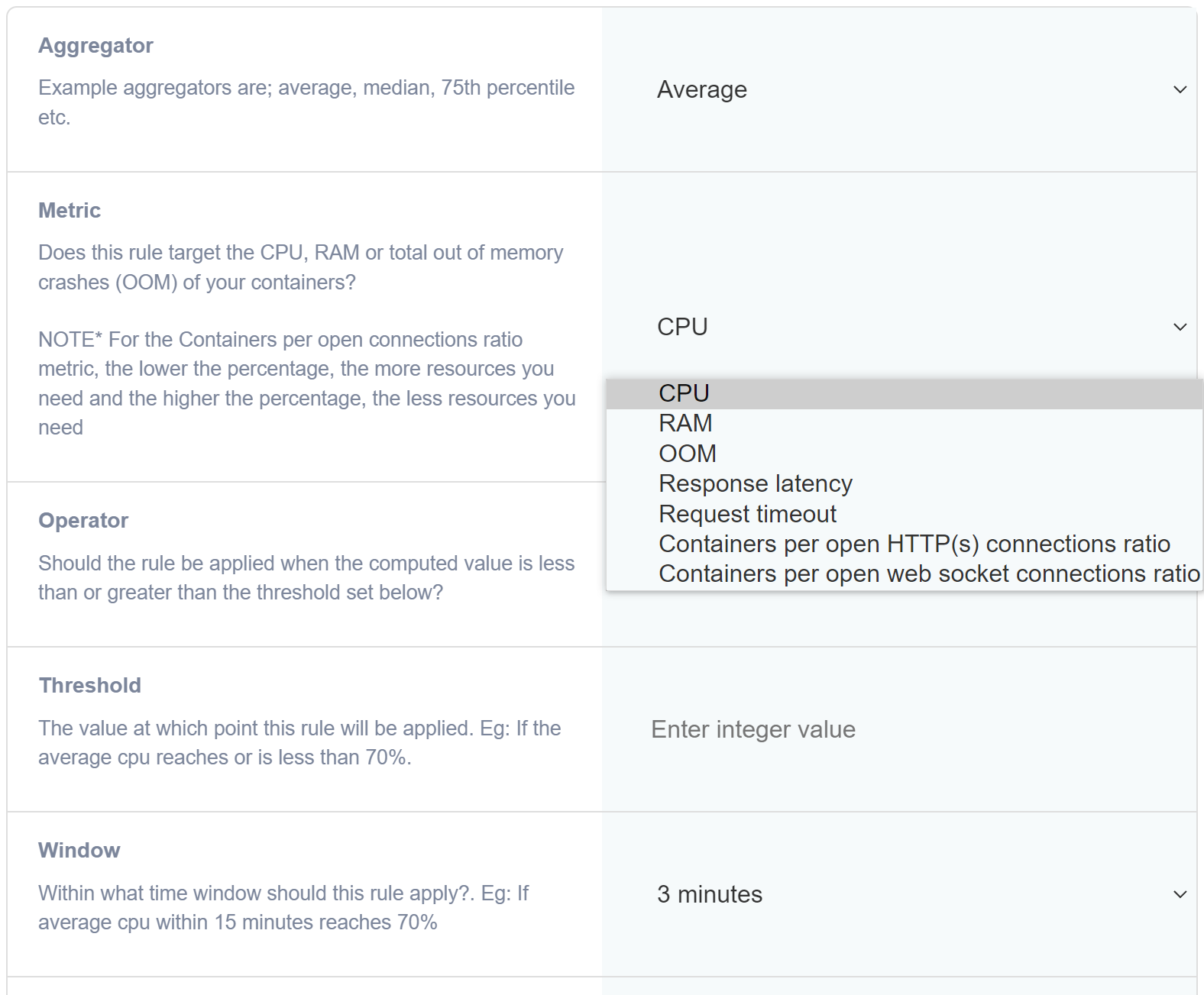
You can set multiple rules and they will all run concurrently and triggered when the rule is matched. This allows you to set rules to both scale out and scale back in. In the below section we explain the various metrics and how they can be used.
CPU Metric
The CPU metric captures the CPU usage of your application containers. Depending on how your application is written, a higher CPU usage could signal a high utilization of the app. For example, if the CPU usage remains constantly at around 80% and never drops down for a period of 3, 5 minutes, this can potentially signal a need for resources. Of course, it can also be the case, this is simply how your application works. You will have to determine what a high or low CPU usage means in your case.
RAM Metric
Pretty self explanatory, captures the memory usage of your app containers.
Response latency
How long is it taking for your app containers to respond to incomming requests? If typically your application respond in 200 milliseconds and all of a sudden there is a spike to about 5000 milliseconds and remains so for about 3 or 5 minutes, this can possibly signal a need for more compute resources to scale the application.
Request timeout
The NodeChef load balancer imposes a 120 seconds timeout for your app containers to respond to incomming request. If the load balancer recieves no response in 120 seconds, the request is aborted and an HTTP 500 status is relayed back to the client. Typically a high response latency plus high requests timeout and a high CPU usage is most likely a sign of an undersized deployment. By monitoring your application from time to time, you should be able to easily tell what is normal and what is abnormal for your deployment.
Connections per open HTTP(s) connections ratio
This metric is computed as (total_containers / total_http_connections) * 100. The lower the value, that means a smaller amount of app containers can handle multiple concurrent connections. For API based applications, this metric can be very useful for scaling. For example: imagine in the evenings say after 8pm the amount of concurrent connections drop significantly and then picks up gradually the next morning and peaks in the afternoon. By setting a rule to use this ratio, your deployment can scale down nicely as traffic goes down in the evenings and gradually add back the containers the next morning and peak during the day. This is the metric we personally use for our scaling needs. For websocket applications like Meteor.js or Socket.js, you will use the Connections per open web socket connections ratio.
Connections per open web socket connections ratio
This metric is computed as (total_containers / total_websockets) * 100. It is the same concept as the HTTP(s) metrics explained above. The only difference been the web socket variant is targed towards web socket applications such as Meteor.js, Socket.js etc.
Conclusion
Auto scaling can be tricky to implement, and we advice you start of by manually scaling your deployments in response to a change in any of the above metrics. For example you can set an alert instead of scaling right away. Once you review the alert, you can manually scale the application and monitor how it is doing there after. With time as you familiarize yourself with what works for your app. You can easily set the rules to trigger the scaling on your behalf. We hope this part provided you with good information on the auto scaling feature on NodeChef.